统计学习方法 提升方法
AdaBoost
在概率近似正确(probably approximately correct, PAC)学习的框架中,一个概念(一个类),如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么就称这个概念是强可学习的;一个概念,如果存在一个多项式的学习算法能够学习它,学习的正确率仅比随机猜测略好,那么就称这个概念是弱可学习的.
如果已经发现了“弱学习算法”,将它提升(boost) 为“强学习算法”.大家知道,发现弱学习算法通常要比发现强学习算法容易得多.那么如何具体实施提升,便成为开发提升方法时所要解决的问题.关于提升方法的研究很多,有很多算法被提出.最具代表性的是AdaBoost算法。
对于分类问题而言,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确的分类规则(强分类器)容易得多.提升方法就是从弱学习算法出发, 反复学习,得到一系列弱分类器(又称为基本分类器),然后组合这些弱分类器,构成一个强分类器.大多数的提升方法都是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布调用弱学习算法学习一系列弱分类器.
对提升方法来说,有两个问题需要回答:一是在每一轮如何改变训练数据的权值或概率分布;二是如何将弱分类器组合成一个强分类器.关于第1个问题,AdaBoost的做法是,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值.这样一来,那些没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分类器的更大关注.于是,分类问题被一系列的弱分类器“分而治之”.至于第2个问题,即弱分类器的组合,AdaBoost 采取加权多数表决的方法.具体地,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用.
AdaBoost算法
给定一个二类分类的训练数据集。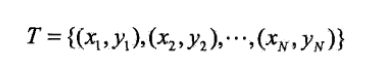
算法(AdaBoost)


AdaBoost的例子




AdaBoost算法的训练误差分析
AdaBoost最基本的性质是它能在学习过程中不断减少训练误差,即在训练数据集上的分类误差率。
定理(AdaBoost的训练误差界)
AdaBoost算法最终分类器的训练误差界为: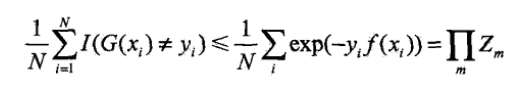
这一定理说明,可以在每一轮选取适当的Gm使得Zm最小,从而使训练误差下降最快。对二类分类问题,有如下结果:
定理(二类分类问题AdaBoost的训练误差界)
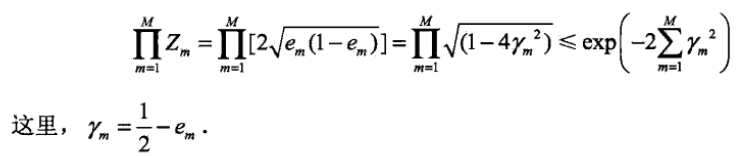
推论

这表明在此条件下AdaBoost的训练误差是以指数速率下降的。这一性质当然很有吸引力。
AdaBoost算法不需要知道下界y.与早期的提升方法不同,AdaBoost具有适应性,即它能适应弱分类器各自的训练误差率。
AdaBoost算法的解释
AdaBoost算法还有另一个解释,即可以认为AdaBoost算法是模型为加法模型、损失函数为指数函数、学习算法为前向分布算法时的二类分类学习方法。
前向分布算法
考虑加法模型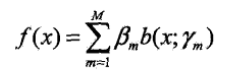
其中b(x;ym)为基函数,ym为基函数的参数,Bm为基函数的系数。
在给定训练数据及损失函数L(y,f(x))的条件下,学习加法模型f(x)成为损失函数极小化问题。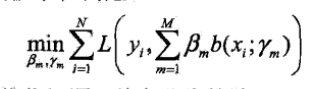
通常这是一个复杂得优化问题。前向分步算法求解这一优化问题的想法是,因为学习的是加法模型,如果能够从前向后,每一步只学习一个基函数及其系数,逐步逼近目标函数式,就可以简化优化的复杂度。具体的,每步只需优化损失函数: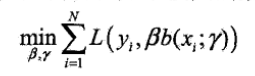
前向分步算法

前向分步算法与AdaBoost
定理
AdaBoost算法是前向分步算法加法算法的特例。这时模型是由基本分类器组成的加法模型,损失函数是指数函数。
提升树
提升树是以分类树或回归树为基本分类器的提升方法.提升树被认为是统计学习中性能最好的方法之一。
提升树模型
提升方法实际采用加法模型(即基函数的线性组合)与前向分步算法。以决策树为基函数的提升方法称为提升树(boosting tree)。对分类问题决策树是二叉分类树,对回归问题决策树是二叉回归树。基本分类器x<v,或x>v,可以看做是由一个根结点直接连接两个叶节点的简单决策树,即所谓的决策树桩。提升树模型可以表示为决策树的加法模型: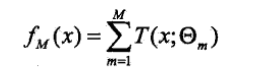
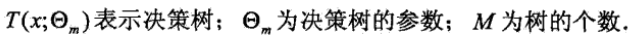
提升树算法
提升树算法采用前向分步算法.首先确定初始提升树f0(x)=0,第m步的模型是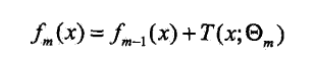
其中,fm-1(x)为当前模型,通过最小化损失函数确定下一棵决策树的参数θm。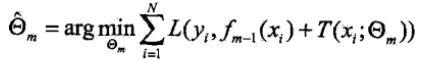
由于树的线性组合可以很好地拟合训练数据,即使数据中的输入与输出之间的关系很复杂也是如此,所以提升树是一个高功能的学习算法.
针对不同问题的提升树学习算法,其主要区别在于使用的损失函数不同.包括用平方误差损失函数的回归问题,用指数损失函数的分类问题,以及用一般损失函数的一般决策问题.
基函数是分类树(二叉分类树)
对于基函数是分类树时,我们使用指数损失函数,此时正是AdaBoost算法的特殊情况,即将AdaBoost算法中的基分类器使用分类树即可。
回归问题的提升树算法(基函数是回归树)

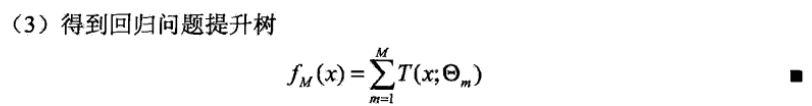
例



梯度提升
提升树利用加法模型与前向分步算法实现学习的优化过程.当损失函数是平方损失和指数损失函数时,每一步优化是很简单的.但对一一般损失函数而言,往往每一步优化并不那么容易.针对这一问题,Freidman 提出了梯度提升(gradient
boosting)算法,这是利用最速下降法的近似方法,其关键是利用损失函数负梯度在当前模型的值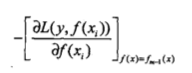
作为回归问题提升树算法中的残差的近似值,拟合一个回归树。
梯度提升算法


博客
Bagging + 决策树 = 随机森林
AdaBoost + 决策树 = 提升树
Gradient Boosting + 决策树 = GBDT
实践
AdaBoost单层决策树
分类问题。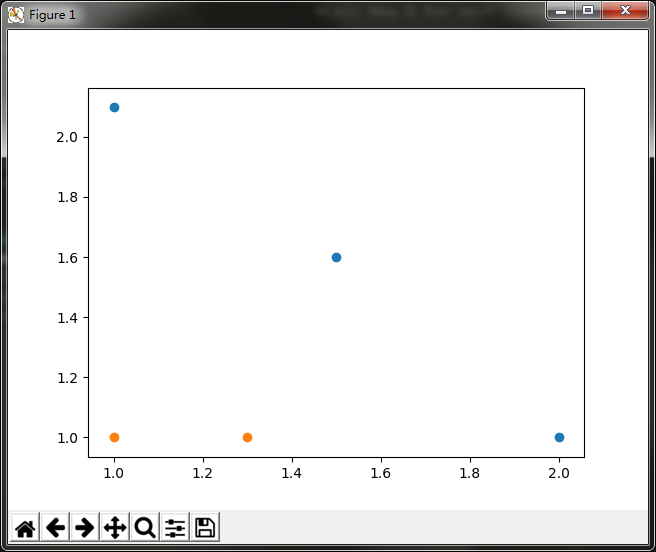
可以看到,如果想要试着从某个坐标轴上选择一个值(即选择一条与坐标轴平行的直线)来将所有的蓝色圆点和橘色圆点分开,这显然是不可能的。这就是单层决策树难以处理的一个著名问题。通过使用多颗单层决策树,我们可以构建出一个能够对该数据集完全正确分类的分类器。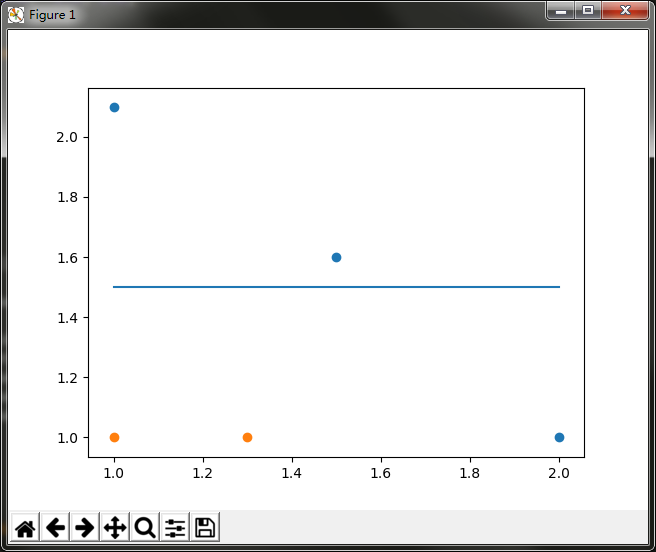
蓝横线上边的是一个类别,蓝横线下边是一个类别。显然,此时有一个蓝点分类错误,计算此时的分类误差,误差为1/5 = 0.2。这个横线与坐标轴的y轴的交点,就是我们设置的阈值,通过不断改变阈值的大小,找到使单层决策树的分类误差最小的阈值。同理,竖线也是如此,找到最佳分类的阈值,就找到了最佳单层决策树。
通过遍历,改变不同的阈值,计算最终的分类误差,找到分类误差最小的分类方式,即为我们要找的最佳单层决策树。这里lt表示less than,表示分类方式,对于小于阈值的样本点赋值为-1,gt表示greater than,也是表示分类方式,对于大于阈值的样本点赋值为-1。经过遍历,我们找到,训练好的最佳单层决策树的最小分类误差为0.2,就是对于该数据集,无论用什么样的单层决策树,分类误差最小就是0.2。这就是我们训练好的弱分类器。接下来,使用AdaBoost算法提升分类器性能,将分类误差缩短到0。此时使用AdaBoost提升分类器性能。
MLcode/AdaBoost单层决策树.py at master · zdkswd/MLcode · GitHub
通过改变样本的权值,会改变分类误差率,以选择分类误差率最小的弱选择器。
scikit-learn AdaBoost
sklearn.ensemble.AdaBoostClassifier共有五个参数,参数说明。
- base_estimator:默认为DecisionTreeClassifier。理论上可以选择任何一个分类或者回归学习器,不过需要支持样本权重。AdaBoostClassifier默认使用CART分类树DecisionTreeClassifier,而AdaBoostRegressor默认使用CART回归树DecisionTreeRegressor。另外有一个要注意的点是,如果我们选择的AdaBoostClassifier算法是SAMME.R,则我们的弱分类学习器还需要支持概率预测,也就是在scikit-learn中弱分类学习器对应的预测方法除了predict还需要有predict_proba。
- algorithm:可选参数,默认为SAMME.R。scikit-learn实现了两种Adaboost分类算法,SAMME和SAMME.R。两者的主要区别是弱学习器权重的度量,SAMME使用对样本集分类效果作为弱学习器权重,而SAMME.R使用了对样本集分类的预测概率大小来作为弱学习器权重。由于SAMME.R使用了概率度量的连续值,迭代一般比SAMME快,因此AdaBoostClassifier的默认算法algorithm的值也是SAMME.R。我们一般使用默认的SAMME.R就够了,但是要注意的是使用了SAMME.R, 则弱分类学习器参数base_estimator必须限制使用支持概率预测的分类器。SAMME算法则没有这个限制。
- n_estimators:整数型,可选参数,默认为50。弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是50。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑。
- learning_rate:浮点型,可选参数,默认为1.0。每个弱学习器的权重缩减系数,取值范围为0到1,对于同样的训练集拟合效果,较小的v意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。所以这两个参数n_estimators和learning_rate要一起调参。一般来说,可以从一个小一点的v开始调参,默认是1。
- random_state:整数型,可选参数,默认为None。如果RandomState的实例,random_state是随机数生成器; 如果None,则随机数生成器是由np.random使用的RandomState实例。
https://github.com/zdkswd/MLcode/tree/master/scikit-learn-code/scikit-learn-AdaBoost